Почему новый процессор быстрее на такой же частоте?

Мы независимо проверяем товары и технологии которые рекомендуем.

Если вы готовы самостоятельно выбирать процессор, то рекомендуем воспользоваться профильным разделом каталога. Тут можно отсортировать подходящие модели по различным параметрам, в том числе тактовым частотам, поколениям (кодовым названиям), объему кэш-памяти и т.д.
Почему частота процессоров почти не растет?
В конце 90-х годов 20 века со скоростью роста тактовых частот процессоров мог конкурировать разве что темп инфляции. От десятков МГц процессоры быстро перешли к сотням, а затем и к ГГц. Этот рост давал увеличение количества выполняемых в секунду операций, то есть прямо повышал быстродействие. Но уже в середине «нулевых» годов данная гонка застопорилась. Условный Pentium 4 тех лет имел около 3 ГГц, а сегодня у многих Core i5 сопоставимые частоты.
Больше 10 лет активного прироста нет. Почему так? Прежде всего из-за тепловыделения (TDP). Чтобы дальше поднимать частоту чипов надо увеличивать рабочее напряжение. Оно прямо влияет на количество выделяемого тепла процессором — его многочисленными транзисторами.
Так, чтобы двукратно увеличить тактовую частоту, придется поднять тепловыделение приблизительно в 8 раз. В таком сценарии точно не обойтись без крутой системы охлаждения, вероятно, водяной. Из-за того, что рост «герцовок» уперся в показатели TDP инженерам пришлось менять подходы к работе.

Еще повышать частоты можно за счет совершенствования техпроцессов. Логика тут такова: чем меньше будут составные части чипа, тем быстрее пройдут сигналы и выше окажется скорость работы. Переход на более тонкие техпроцессы происходит в режиме нон-стоп: в 2024 году уже добрались до 4 нм, а 10 лет назад 22 нм были откровением.
Правда, на практике ощутимого прироста частот более тонкий техпроцесс не дает. Просто пока нанометры (нм) уменьшаются, физические размеры кристаллов растут, увеличивается количество ядер, а значит сигналы преодолевают почти такие же расстояния, что и раньше.
Выходит так, что до нового технологического прорыва в процессоростроении не стоит ожидать активного роста частот. А значит прирост быстродействия будет происходить за счет других методов оптимизации.

Что сегодня делает процессоры быстрее?
Сегодня увеличивать производительность и быстродействие чипов помогает оптимизация процессорной микроархитектуры, которая нацелена на:
- вычислительные ядра;
- подсистемы памяти (различные виды кэша и промежуточные буферы обмена);
- шины передачи данных.
Основная работа инженеров Intel и AMD зачастую направлена на увеличение показателя Instruction Per Clock (IPC) — количества исполняемых инструкций за такт. Если удается поднять IPC, то процессор делает больше вычислений и работает быстрее, чем его предшественники. С нуля чипы делаются крайне редко: обычно новое поколение — это результат устранения имеющихся «узких мест», доработки существующих блоков, программной оптимизации и т.д.
Косвенным методом повышения эффективности чипов выступает снижение тепловыделения на каждую вычислительную операцию. Но это не столько фактор быстродействия, сколько способ повысить стабильность тактовых частот при высоких или предельных нагрузках.
Остановимся на главных способах ускорения современных процессоров подробнее.
Оптимизация вычислительных ядер
Современные чипы придерживаются конвейерной обработки, то есть разбивают поступающие на выполнение инструкции на множество более простых операций. Это напоминает типичный конвейер на заводе, где каждый исполнитель делает только что-то одно. Процессы идут не последовательно, а параллельно, что повышает общую производительность.
Правда, качественные изменения ведут к усложнению процессоров. Так, за каждую операцию в инструкции отвечает свой блок. Плюс в новых поколениях чипов появляются дополнительные элементы, которые призваны ускорить конвейер, поднять его пропускную способность, снизить простои (еще сильнее дробя поступающие инструкции на мелкие операции) и т.д.
Вот лишь некоторые блоки и примеры их модернизации:
- Branch Predictors — предсказатели переходов. Они прогнозируют наперед выполнение тех или иных инструкций от запущенных программ. Улучшения тут сокращает количество ошибочных прогнозов, из-за чего общая производительность повышается.
- Decoders — декодеры. Преобразуют сложные команды от программ в самые простые микрооперации. В новые ядра добавляют больше декодеров, благодаря чему процессор за единицу времени готов выполнять больше инструкций (при условии модернизации и других блоков).
- Schedulers — планировщики исполнения. Это блоки, которые выстраивают очередь из инструкций. Апгрейд планировщика обеспечивает вычислительные ядра работой без простоев.
- Register File — регистровый файл. Элемент, который сохраняет коды команды, пока она исполняется. Модернизация может касаться расширения хранилища, что в свою очередь увеличит пропускную способность по выполняемым операциям.
- Execution Ports — исполнительные порты. Это те самые блоки, которые реализуют отдельные этапы инструкций. Пример улучшения — увеличение числа таких портов. В результате одновременно в работе оказывается больше операций, повышается скорость выполнения инструкций.
- Load/Store — блок сохранения/загрузки. Он отвечает за сохранение и загрузку данных из памяти. Усовершенствование этого блока повышает эффективность взаимодействия процессора с памятью.
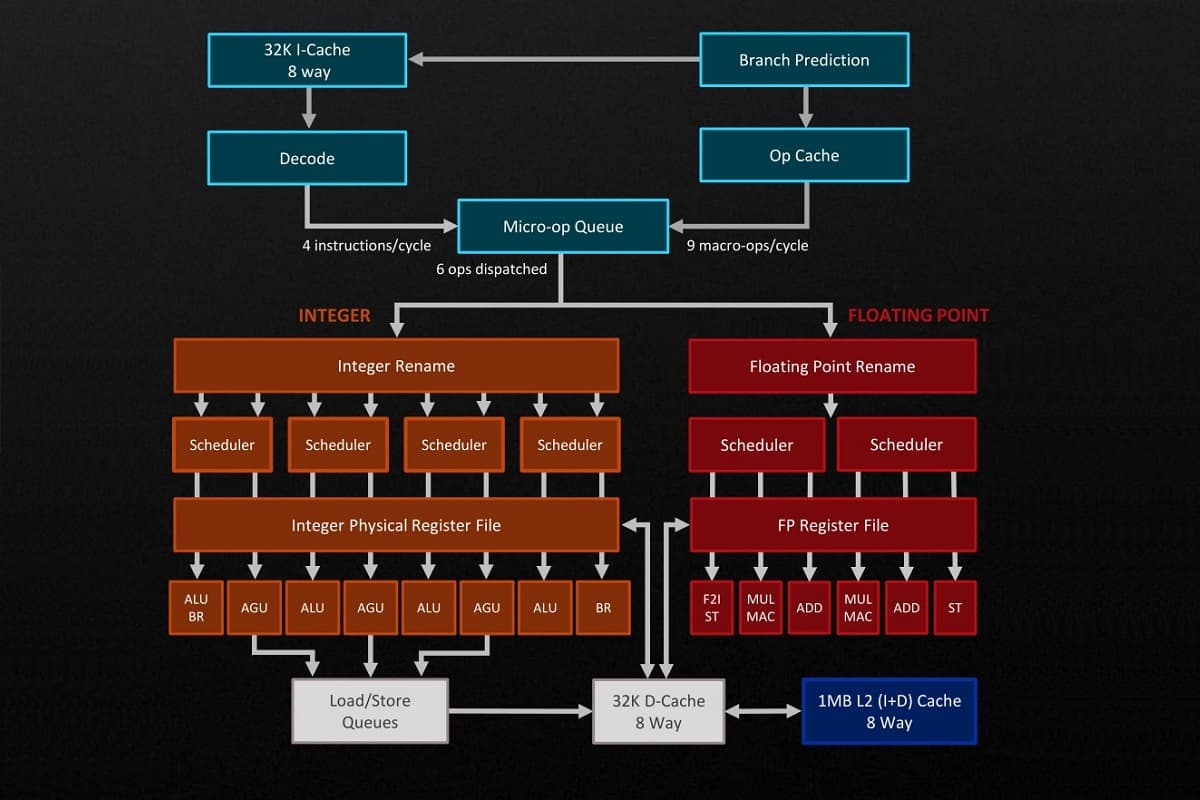
Структура вычислительных ядер сложна, а блоков становится все больше. Но это значит, что и возможности для дальнейшего повышения быстродействия точно не исчерпаны.
Улучшение подсистемы памяти
На количество исполняемых процессором инструкций за такт влияет не только эффективность вычислительных блоков, но и работа подсистемы памяти. В современных чипах обязательно имеется несколько видов кэша и промежуточные буферы. Каждый из уровней от L0 до L3 призван ускорять работу в рамках своей зоны ответственности — определенного вычислительного этапа.
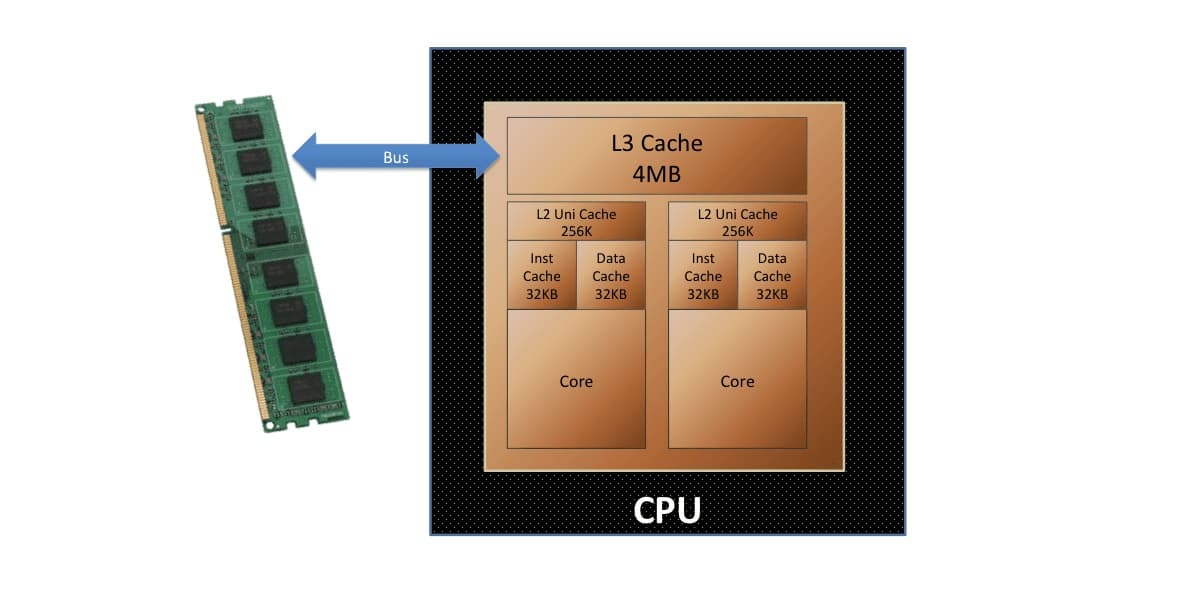
Многоуровневая организация кэша в процессорах используются неслучайно. С увеличением объема память неизменно становится медленнее. Поэтому кэш первого уровня исчисляется килобайтами, но гарантирует максимальное быстродействие. Одновременно и прирост объема кэша L3 (в новых процессорах они порой превышает 100 МБ) тоже обоснован, ведь увеличивает количество данных, которые можно хранить и иметь быстрый доступ к ним.
Итак, самые очевидные методы ускорения процессора за счет подсистемы памяти — увеличивать количество и пропускную способность кэша. Но этим модернизация не ограничивается, а также может включать:
- Изменения в организации кэша. Сегодня все чаще используется так называемый неинклюзивный вариант. Данные не дублируются на всех уровнях кэша, а отслеживаются и подбираются с учетом прогнозов. В результате на L0 находится самое необходимое прямо сейчас, а на L3 — вытесняется ненужное для экономии места.
- Оптимизацию количества каналов. Доступ к данным в кэше зачастую осуществляется по разным «цепочкам». Чем больше каналов, тем выше вероятность найти нужное в подсистеме памяти. Но многоканальность может и усложнить доступ к кэшу, что негативно отразится на производительности. Соответственно, нужно искать оптимальный баланс.
- Увеличение дополнительных (промежуточных) буферов.
А еще для роста вычислительного потенциала и быстродействия компьютера в целом новые процессоры оснащают улучшенными контроллерами — совместимыми с самыми последними поколениями ОЗУ, в том числе DDR5 с высокими частотами.










Ускорение шин передачи данных
В многоядерных процессорах на общее быстродействие влияет скорость передачи данных между вычислительными ядрами и другими компонентами чипа. Соответственно, не последнее значение имеет и применяемая шина.
У каждого производителя используются свои фирменные разработки:
- у Intel — кольцевая шина Ring Bus;
- у AMD — соединительная шина Infinity Fabric.
Как правило, улучшения шин происходят один раз в несколько поколений. Этого достаточно, чтобы покрыть потребности в быстродействии, обусловленные ростом количества и вычислительного потенциала ядер.
Что «ускоряет» процессоры Intel?
Архитектурные улучшения и их влияние на быстродействие наглядно прослеживается на актуальных примерах. У Intel больших скачков тактовых частот нет, но показатели Instruction Per Clock все равно растут. Да, не в каждом поколении, но тенденция очевидна.

В 2021 году компания представила чипы под кодовым названием Rocket Lake. Эти десктопные процессоры 11-го поколения стали «шустрее» предшественников Comet Lake на 10 – 12%. А все благодаря таким архитектурным апгрейдам:
- расширен блок Decoders: стало возможно выполнение 5 инструкций, вместо 4;
- увеличено число исполнительных портов до 10 (ранее было 8);
- модернизирован блок Load/Store;
- выросли объемы промежуточных буферов, кэша L2 и L1;
- ускорен кэш первого уровня.
Через год вышли процессоры Alder Lake и Raptor Lake — соответственно 12-е и 13-е поколение. На фоне предшественника рост быстродействия у этих моделей составил 15 – 20%. Здесь произошли следующие изменения архитектуры:
- снова улучшен декодер — способен выполнять 6 инструкций за такт;
- увеличено число Execution Ports до 12;
- добавлена поддержка ОЗУ DDR5;
- увеличены и ускорены кэши всех уровней, а также промежуточные буферы.
Изменений у Raptor Lake в сравнении с Alder Lake мало. Так, в 13-м поколении чипов увеличилось количество энергоэффективных ядер Gracemont и стало больше кэша L2 и L1. Показатели IPC остались приблизительно на том же уровне.
Поколение Raptor Lake Refresh дебютировало осенью 2023 года и фактически стало косметической доработкой чипов Raptor Lake. Архитектурных изменений тут нет, лишь возросло количество энергоэффективных ядер и внедрены некоторые программные усовершенствования, включая политику диспетчеризации. Апгрейд вылился в увеличение тактовых частот на 100 – 200 МГц. Так, тут есть прямой прирост быстродействия. Он несколько выбивается на фоне актуальных тенденций: его можно считать исключением, которое подтверждает правило.
Основные отличия в микроархитектуре актуальных процессоров Intel (без 14 поколения) сведены в таблицу:
| Кодовое название | Rocket Lake | Alder Lake | Raptor Lake |
|---|---|---|---|
| Поколение | 11 | 12 | 13 |
| Техпроцесс | 14 нм | 10 нм | 10 нм |
| Количество инструкций в работе | 5 | 6 | 6 |
| Число исполнительных портов | 10 | 12 | 12 |
| Увеличение кэша L1 | + (на 150 %) |
+ | - |
| Увеличение кэша L2 | + (на 250 %) |
+ | + (до 2 МБ на ядро) |
| Увеличение кэша L3 | - | + | + (до 4 МБ на кластер) |
| Ускорение кэша | + (для L1) |
+ (для уровней) |
- |
| Другие новшества | апгрейд блока Load/Store, увеличены другие буферы | поддержка ОЗУ DDR5, увеличены другие буферы | больше энергоэффективных ядер Gracemont, поддержка DDR5-5600 |
| Прирост быстродействия на фоне предшественников с той же частотой, в % | 10 – 12 | 15 – 20 | - |





Что «ускоряет» процессоры AMD?
Непосредственное влияние оптимизации процессорной микроархитектуры на скорость работы хорошо заметна и в процессорах AMD. Проследим изменения, начиная с чипов Zen3.
Процессоры AMD с кодовым обозначением Cezanne вышли в конце 2020 года. Это пятое поколение, которое на фоне Zen2 стало на 20% быстрее и догнало по производительности на один поток Intel (отставая до этого много лет). А все благодаря таким улучшениям:
- усовершенствован блок Branch Predictors;
- число исполнительных портов увеличено до 8;
- оптимизированы блоки Schedulers — их стало меньше, но быстродействие удвоилось;
- улучшен блок Load/Store;
- увеличен объем кэша третьего уровня и промежуточных буферов.
В середине 2022 года вышло 6-е поколение процессоров AMD — Zen4 Raphael. Тут произошел переход на 5 нм техпроцесс, плюс были внедрены различные новшества на уровне микроархитектуры, благодаря чему IPC вырос на 13%. Что же стало лучше:
- новый апгрейд предсказателя переходов;
- контроллеры с поддержкой ОЗУ DDR5;
- вдвое увеличен кэш L2 — до 1 МБ на ядро вместо 0.5 МБ;
- модернизирован блок Load/Store;
- увеличен регистровый файл и промежуточные буферы.
В начале 2024 года были представлены гибридные десктопные процессоры Zen4 Phoenix. Изюминка этого поколения — появление компактных вычислительных ядер Zen 4c. Они стали меньше, но сохранили продуктивность (IPC) предшественников Raphael, что говорит и о повышении энергоэффективности. Компактные ядра могут комбинироваться с обычными, что в перспективе добавит вариативности производителям.
Отметим, что летом 2024 года дебютирует новое поколение процессоров AMD — Granite Ridge (Zen5). На момент написания материала они еще не поступили в продажу, но для них заявлен прирост быстродействия (по Instruction Per Clock) на 16%.
Основные отличия в микроархитектурах актуальных процессоров AMD (без Zen5) представлены в таблице:
| Кодовое название | Zen3 Cezanne | AMD Zen4 Raphael | Zen4 Phoenix |
|---|---|---|---|
| Поколение | 6 | 7 | 8 |
| Техпроцесс | 7 нм | 5 нм | 4 нм |
| Улучшение предсказателей переходов | + | + | нет данных |
| Число исполнительных портов | 8 | 8 | 8 |
| Увеличение кэша L1 | - | - | - |
| Увеличение кэша L2 | - | + (до 1 МБ на ядро) |
- |
| Увеличение кэша L3 | + (до 16 МБ на 8 ядер) |
- | - |
| Ускорение кэша | - | - | - |
| Другие новшества | апгрейд блока Load/Store, увеличены другие буферы, используется монолитный кэш L3 | поддержка ОЗУ DDR5, увеличены регистровый файл и другие буферы, апгрейд блока Load/Store | сокращение габаритов вычислительных ядер — появление Zen 4c |
| Прирост быстродействия на фоне предшественников с той же частотой, в % | 20 | 13 | - |
Выводы и рекомендации
При выборе процессора большинство покупателей по привычке смотрят только на таковые частоты и количество ядер, игнорируя другие параметры. В текущих реалиях основной прирост быстродействия кроется в деталях — в оптимизации процессорной микроархитектуры. Поэтому по возможности перед покупкой стоит обращать внимание на новшества в блоках вычислительных ядер, изменения объема кэша разных уровней и даже обновления шин передачи данных.
Основной прирост IPC — количества исполняемых инструкций за такт — обычно дают явные усовершенствования микроархитектуры. Хотя на практике многое зависит и от решаемых задач и конкретных программ. Один софт работает быстрее за счет модернизации вычислительных блоков, а другой — увеличения и ускорения подсистемы памяти.









Cтатьи, обзоры, полезные советы
Все материалы




